.png)
Not All Reachability Is Created Equal
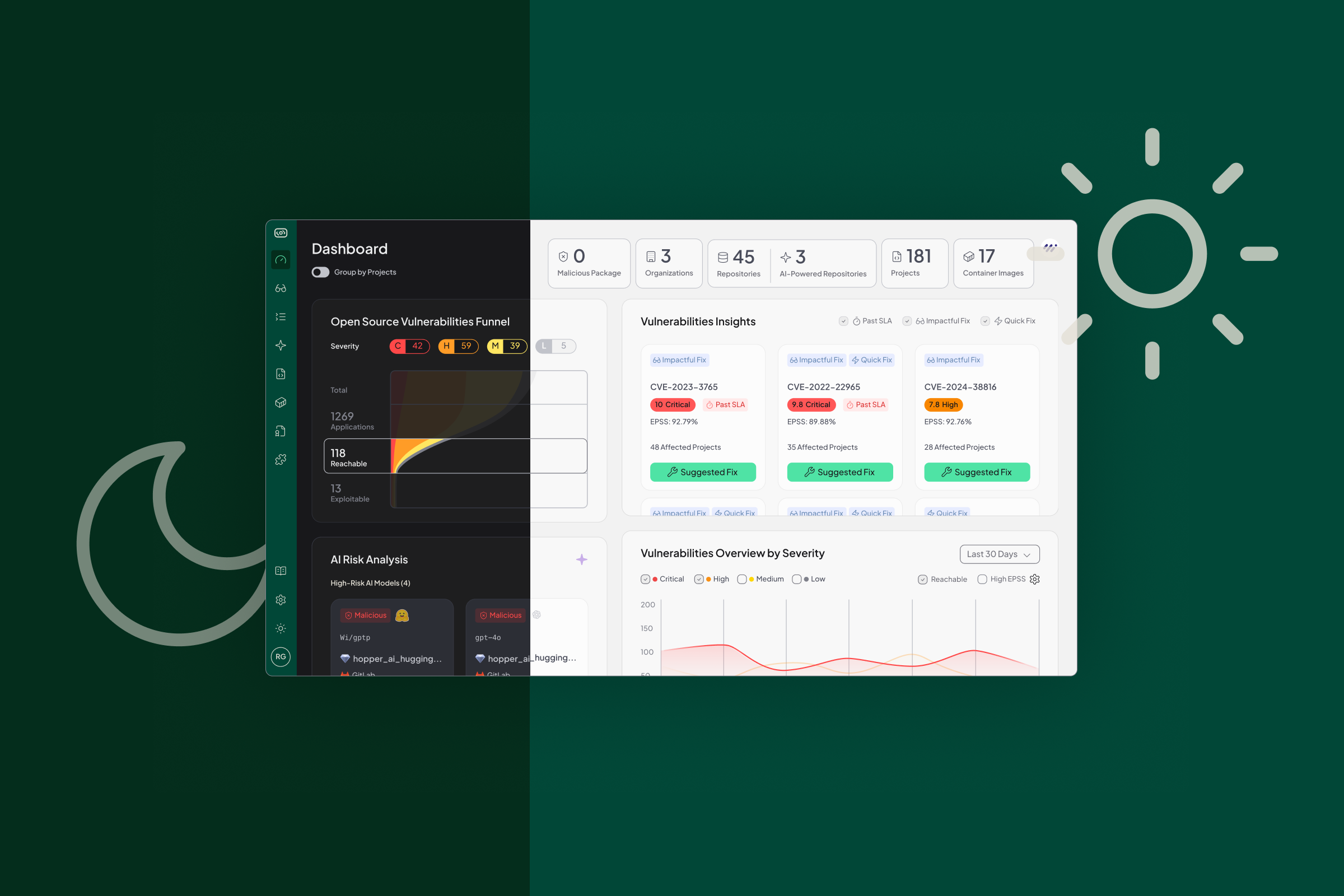
Traditional SCA tools overwhelm teams with hundreds of “critical” vulnerabilities, most of which are never actually reachable in the application. Reachability analysis changes that. It separates theory from reality, helping AppSec teams cut through noise, focus on the vulnerabilities that matter, and build trust with developers.
But not all reachability works the same way. Some methods provide only a rough filter, while others deliver precision down to the function level. The best programs start with function-level analysis at build time, then layer contextual signals such as exposure, policy, and image hygiene.
The challenge? Vendors use “reachability” to mean different things. Let’s clarify the major types of reachability in AppSec, their value, and their limits.
Terminology Note:
In this post, reachable means there is a code path from your application into the vulnerable code. Exploitability is distinct. From a code perspective, it depends on preconditions like input, permissions, architecture, compensating controls, and runtime context. In practice, most security teams layer this with signals such as EPSS scores, CISA KEV listings, or External Attack Surface Management (EASM) findings to assess the real-world likelihood of exploitation.
Package-Level Reachability
Package-level reachability is measured in two ways and asks two simple questions: is the package imported, and is it referenced?
Package-level reachability methods include:
- Import presence: looks for the package in manifests and import statements. Quick triage, especially in ecosystems where dependency trees bloat, such as JavaScript.
- Call presence: analyzes code to see if any function or API from the package is actually called at least once.
Function-Level Reachability
This is the gold standard. Function-level reachability identifies whether the specific vulnerable function is actually callable in your application.
Internet Reachability
Internet reachability focuses on exposure: is the vulnerable service or workload internet-facing?
*As outlined in the FedRAMP RFC 0012 proposal on secure software development attestation, exposure awareness is becoming a formal compliance requirement.
Runtime Reachability, Including eBPF
Runtime reachability tracks which code paths actually execute when an application runs. It relies on agents, language-level hooks, or kernel telemetry to observe live behavior in production or staging environments. These methods provide high-certainty confirmation of execution, but their visibility depends on runtime coverage.
eBPF: Runtime Clarity, Reachability Gaps
The Extended Berkeley Packet Filter (eBPF) is one of the most transformative kernel technologies in modern Linux. It allows small, sandboxed programs to run safely inside the kernel, enabling developers to trace functions and monitor performance.
But despite its flexibility, eBPF is still a runtime technology, not a code analysis tool. It observes what executes, but cannot infer the broader logical or static structure of an application. For example:
- It cannot build a complete dependency graph or determine which code could execute under different conditions.
- It lacks context on both direct and transitive dependencies, making it impossible to trace how a vulnerability propagates through the dependency tree. Because of this, it also cannot calculate the personalized fix for the specific direct dependency that needs to be updated.
- Its visibility is further limited by traffic coverage and sampling; dormant paths or code that never executed during observation remain invisible (a typical sample rate goes as high as 20 times per second only).
In short:
- eBPF captures runtime activity, not build-time reachability.
- It offers execution evidence, but no code-level traceability for root cause or remediation.
- It’s most effective when paired with static or hybrid reachability analysis that maps the potential paths before deployment
Pulling It All Together: The Reachability Matrix
Here’s how the main types of reachability compare at a glance:
The Hopper Point of View
At Hopper, we see reachability as more than a single filter. It is a layered methodology that combines precision, context, and developer usability.
- Function-level reachability: Cuts more than 93% of noise by analyzing whether vulnerable functions are actually callable. Powered by Hopper’s proprietary vulnerability database, which includes function-level context for every CVE, delivering unmatched accuracy.
- Exploitability context: Incorporates signals like EPSS scores and CISA KEV to prioritize vulnerabilities more effectively.
- Business context: Highlights issues in crown-jewel applications and maps findings against SLA commitments.
- Framework and code complexity support: Handles dynamic loading, reflection, shaded libraries, and framework-driven calls with ease, even in complex environments such as Spring, Django, and ASP.NET where conventional tools miss critical paths.
- Internal library detection: Surfaces risks in proprietary or shared internal packages.
From there, Hopper pairs reachability insights with developer-friendly remediation: call graphs that trace vulnerable functions, direct links to manifest and source files (for example, pom.xml), and references back to the relevant function calls in Git for first-party code.
This combination of methodologies makes Hopper the most accurate and developer-friendly reachability platform. Trusted by security teams to reduce wasted cycles, and by developers to fix only what matters.
Noise Reduction Starts with Reachability
Reachability helps teams cut through noise and focus on vulnerabilities that truly matter. Among the different types, function-level reachability delivers the precision AppSec programs need when paired with business context and developer-friendly remediation.
Hopper brings these elements together in a way that is both accurate and usable, giving security teams clarity and developers guidance they can trust.

Val is the VP of Marketing at Hopper, where she leads brand, launch, and go-to-market strategy. She brings over 15 years of experience across B2B cybersecurity and B2C experiential marketing. Based in Northern VA with her partner, 3 daughters, and 3 dogs. When she's not wrangling family, she enjoys gardening, pilates, and strategy games (including RPG and puzzles)!